How Peptides Differ from Proteins: A Research Explainer
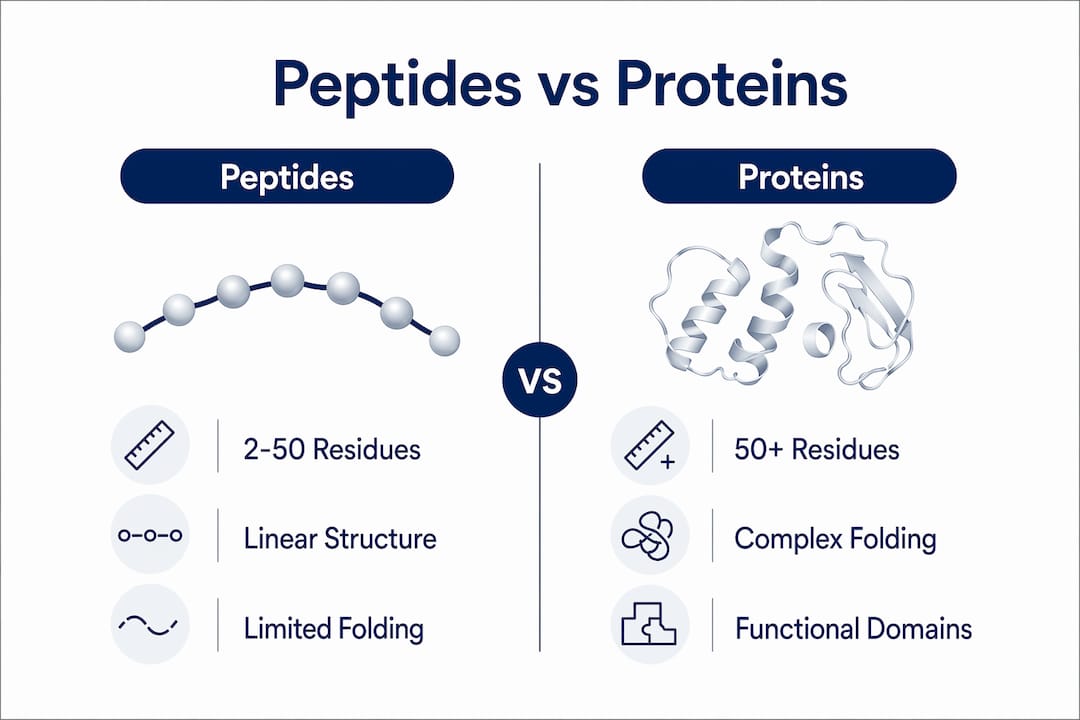
Peptides are defined as short amino acid chains consisting of 2 to 50 residues, while proteins are longer polypeptide chains that fold into stable secondary, tertiary, and quaternary three-dimensional structures. Understanding how peptides differ from proteins is a foundational requirement for accurate experimental design, data interpretation, and literature review in life sciences. Both molecule classes share the same backbone chemistry, specifically peptide bond formation/12%3A_Biomolecules_-_Amino_Acids_Peptides_and_Proteins/12.04%3A_Peptides_and_Proteins) via condensation of amino and carboxyl groups, yet their structural and functional properties diverge substantially at the chain length threshold. This distinction matters not only for classification but also for how researchers design assays, select reagents, and interpret proteomics data.
How peptides differ from proteins: structure and chemistry explained
The primary structural distinction between peptides and proteins is chain length, and that length directly determines whether a molecule can fold into a stable higher-order structure. Peptides range from 2 to 50 amino acids, while proteins are generally defined as chains of 50 or more residues. This is a practical convention, not an arbitrary cutoff. Chains below approximately 50 residues typically lack the mass and sequence complexity needed to sustain stable secondary or tertiary folding under physiological conditions.
Both peptides and proteins share a primary structure: a linear sequence of amino acids connected by covalent amide bonds/12%3A_Biomolecules_-_Amino_Acids_Peptides_and_Proteins/12.04%3A_Peptides_and_Proteins). Each additional residue adds one peptide bond to the chain, and this backbone chemistry is identical across both classes. The divergence begins at the level of secondary structure, where proteins form alpha helices and beta sheets, and continues through tertiary folding and, in some cases, quaternary assembly of multiple subunits. Peptides generally do not achieve these higher-order configurations in solution.

Disulfide bridges, formed between cysteine residues, contribute significantly to protein structural stability. These covalent crosslinks lock folded conformations in place, enabling the precise active site geometries required for enzymatic function and receptor binding. Most peptides lack the length and cysteine content to form these stabilizing networks, which is one reason their conformational behavior in solution differs so markedly from that of proteins.
Pro Tip: When reviewing literature, note whether the authors use “polypeptide” as a synonym for protein or as a neutral chain-length descriptor. Polypeptide technically refers to any amino acid chain regardless of length, so context determines meaning. Misreading this can lead to classification errors in annotation work.
How do functional roles differ between peptides and proteins in biology?
The role of peptides in biology centers primarily on signaling. Peptides function as chemical messengers, hormones, and receptor ligands, with insulin and oxytocin representing well-characterized examples. These molecules achieve receptor specificity through precise sequence composition and, in some cases, constrained conformations, despite lacking the elaborate folded architectures of proteins. Their compact size allows rapid synthesis, secretion, and clearance, properties that suit their roles as fast-acting molecular signals.
Proteins, by contrast, perform a broader range of biological functions enabled by their structural complexity:
- Enzymatic catalysis: Active sites formed by tertiary folding catalyze specific biochemical reactions with high selectivity. Enzymes such as trypsin, lysozyme, and DNA polymerase depend entirely on three-dimensional structure for function.
- Structural support: Collagen, keratin, and actin provide mechanical integrity to tissues and cells. These functions require extended, stable polymer assemblies that only proteins can form.
- Molecular transport: Hemoglobin transports oxygen through cooperative binding enabled by its quaternary structure. No peptide performs an equivalent function.
- Immune recognition: Antibodies, including monoclonal antibodies used in research and therapeutics, are glycoproteins whose antigen-binding specificity depends on folded variable domains.
Insulin occupies a well-documented boundary position. At 51 amino acids with two disulfide-linked chains, insulin is classified as a protein hormone because its folded three-dimensional structure is required for receptor binding. This makes insulin a useful teaching case: chain length alone does not determine classification when folding and function are considered together. Researchers working with peptide hormone research models should account for this overlap when designing binding assays or selecting reference standards.
What are the scientific nuances and exceptions in classifying peptides and proteins?
Classification becomes more complex when molecular mass is introduced as a criterion. Polypeptides with a molecular mass of approximately 10,000 Da or more are conventionally classified as proteins, linking the definition to both residue count and mass. This dual criterion reflects the reality that amino acid composition affects molecular weight independently of chain length. A 50-residue chain of large aromatic amino acids will have a substantially different mass than a 50-residue chain of glycine residues.
The emergence of micropeptides has added a further layer of complexity to this classification framework. Micropeptides are polypeptides of fewer than approximately 100 to 150 amino acids, produced from lncRNAs, circRNAs, and untranslated mRNA regions that were previously annotated as noncoding. These molecules are functionally significant despite their small size, with documented roles in cancer biology, immune regulation, and metabolic signaling. Their discovery has forced a reassessment of genome annotation pipelines that historically excluded short open reading frames from protein-coding catalogs.
| Classification term | Residue range | Key structural feature | Example |
|---|---|---|---|
| Peptide | 2 to 50 aa | No stable higher-order folding | Oxytocin (9 aa) |
| Polypeptide | Any length | Linear chain descriptor | Precursor proteins |
| Protein | ~50 aa and above | Secondary, tertiary, quaternary folding | Hemoglobin |
| Micropeptide | Under ~150 aa | Functional short peptide from sORFs | MOTS-c (16 aa) |
The concept of “peptideins,” a term emerging from recent proteomics literature, refers to functional microproteins that blur the boundary between peptides and small proteins. These molecules challenge the assumption that biological function scales with molecular size. New research on microproteins and peptideins suggests the known proteome is substantially larger than current databases reflect, with implications for biomarker discovery and functional genomics.
Pro Tip: When annotating sequencing data, apply a residue count filter of at least 100 amino acids before excluding candidates from protein-coding analysis. Applying the traditional 50-residue cutoff risks discarding functionally relevant micropeptides that current databases have not yet cataloged.
How do researchers analyze and differentiate peptides and proteins in the laboratory?
Laboratory differentiation of peptides and proteins follows a defined analytical workflow. The standard approach for proteomics proceeds as follows:
- Protein extraction and denaturation. Cell lysates or tissue samples are processed under denaturing conditions to unfold proteins and expose cleavage sites.
- Protease digestion. Trypsin cleaves proteins at the C-terminal side of lysine and arginine residues, generating peptide fragments suitable for mass spectrometry analysis. This step converts proteins into detectable peptide-length products.
- Chromatographic separation. Reversed-phase liquid chromatography separates peptide fragments by hydrophobicity before they enter the mass spectrometer.
- Mass spectrometry detection. Fragment ion spectra are matched against sequence databases to identify parent proteins. Small peptides and microproteins can be difficult to detect because trypsin digestion of very short sequences produces fragments too small for reliable database matching.
- Bioinformatic classification. Sequence length, molecular weight, and predicted folding are used to classify detected molecules as peptides or proteins within the analytic pipeline.
Sequence directionality is a non-negotiable convention in this workflow. Peptide and protein sequences are written from the N-terminus to the C-terminus/12%3A_Biomolecules_-_Amino_Acids_Peptides_and_Proteins/12.04%3A_Peptides_and_Proteins), and this directionality governs protease cleavage site mapping and mass spectrometry fragmentation interpretation. Reversing this convention in sequence input files produces incorrect fragment assignments and unreliable identification results. Researchers using peptide sequence characterization methods should verify that all bioinformatic tools apply N-to-C directionality by default.
Pro Tip: When working with samples that may contain micropeptides, consider enrichment strategies such as size exclusion chromatography prior to trypsin digestion. This separates small peptides from larger proteins before digestion, preserving intact micropeptide sequences for direct detection rather than fragmenting them further.
What practical implications do the differences between peptides and proteins have for biomedical research?
The structural differences between peptides and proteins translate directly into distinct research and development profiles. Key practical distinctions include:
- Drug class separation. Peptide drugs such as insulin and semaglutide are synthesized chemically and have molecular weights typically below 10 kDa. Protein biologics such as monoclonal antibodies are produced in cell culture systems and have molecular weights in the 150 kDa range. These differences affect formulation, storage, and analytical characterization requirements.
- Stability profiles. Peptides are generally more susceptible to proteolytic degradation in biological matrices than folded proteins. This affects assay design when peptides are used as research standards or biomarkers.
- Reagent purity requirements. Research reproducibility depends on the purity and identity of peptide reagents. Impurities in synthetic peptides can generate artifactual signals in binding assays, cell-based models, and mass spectrometry experiments.
- Regulatory and compliance context. Peptides used in laboratory research are subject to research-use-only designations in many jurisdictions. Understanding the structural basis for these classifications supports accurate regulatory documentation.
The role of peptide biomarkers in drug discovery has grown substantially as proteomics technologies have improved sensitivity for low-abundance short peptides. Researchers selecting peptide reference standards for biomarker assays should prioritize materials with verified sequence identity and documented purity, confirmed through techniques such as HPLC and LC-MS. Peptide manufacturing quality benchmarks directly affect the reliability of downstream experimental data, particularly in quantitative proteomics and receptor binding studies.
Key takeaways
Peptides and proteins share identical backbone chemistry but diverge at the ~50 amino acid threshold, where chain length enables stable three-dimensional folding and the full range of protein biological functions.
| Point | Details |
|---|---|
| Length defines the boundary | Peptides contain 2 to 50 amino acids; proteins contain approximately 50 or more residues with stable folding. |
| Shared backbone chemistry | Both classes are linked by covalent peptide bonds formed from amino and carboxyl group condensation. |
| Functional divergence | Peptides primarily signal via receptors; proteins perform catalysis, transport, structural, and immune functions. |
| Micropeptides challenge definitions | Functional peptides under 150 amino acids from noncoding regions expand the known proteome and require updated annotation. |
| Purity matters for research | Verified sequence identity and documented purity are required for reliable peptide reagent performance in laboratory assays. |
Why precise classification matters more than most researchers assume
We work directly with the research community on peptide characterization and supply, and one pattern stands out consistently: the peptide-protein boundary is treated as settled when it is not. Most researchers apply the 50-residue rule without accounting for molecular mass, folding behavior, or the expanding micropeptide literature. That gap in classification rigor creates real problems downstream, particularly in proteomics pipelines where small functional molecules are systematically excluded from analysis.
The misconception that peptides are simply smaller proteins is understandable given their shared chemistry, but it obscures a functionally significant distinction. A 9-residue peptide like oxytocin achieves receptor specificity through sequence alone, without any folded architecture. A 51-residue molecule like insulin requires disulfide-stabilized folding to bind its receptor. Treating these as points on a single continuum misses the mechanistic differences that matter for experimental interpretation.
What concerns us more is the emerging micropeptide literature. Functional molecules under 100 amino acids, produced from genomic regions that annotation pipelines still flag as noncoding, are being identified with increasing frequency. Researchers who have not updated their classification frameworks since graduate training are likely missing these molecules entirely in their data. The practical fix is straightforward: revise residue count filters in bioinformatic pipelines and apply enrichment steps before trypsin digestion when small peptides are a plausible component of the sample.
Precise definitions are not academic formalities. They determine what you detect, what you annotate, and what conclusions you draw from your data.
— Vertex
Research-grade peptides for life sciences investigations
Vertexpeptideslab supplies laboratory-grade synthetic peptides for non-clinical research applications, including catalog compounds such as TB-500, IGF-1 LR3, and Ipamorelin, as well as custom synthesis options. Every batch is supported by a Certificate of Analysis confirming purity above 99% through third-party HPLC and LC-MS verification. Researchers requiring traceable, batch-verified materials for proteomics, receptor binding studies, or biomarker assay development can explore the research catalog for current inventory and COA documentation. U.S.-based fulfillment supports reliable delivery timelines for qualified research institutions. For laboratory research use only. Not for human or veterinary use.
FAQ
What is the difference between a peptide and a protein?
A peptide is an amino acid chain of 2 to 50 residues that generally lacks stable three-dimensional folding, while a protein is a longer chain of approximately 50 or more amino acids that folds into secondary, tertiary, and in some cases quaternary structures. Both are linked by covalent peptide bonds, but chain length determines whether higher-order folding is achievable.
Why is insulin classified as a protein if it has only 51 amino acids?
Insulin is classified as a protein hormone because its disulfide-stabilized three-dimensional structure is required for receptor binding, not simply because of its residue count. This makes insulin a boundary case that illustrates how folding and function, not length alone, determine classification.
What are micropeptides and why do they matter?
Micropeptides are functional polypeptides of fewer than approximately 100 to 150 amino acids, produced from genomic regions previously annotated as noncoding. Their discovery expands the known proteome and requires updated annotation pipelines that do not exclude short open reading frames from protein-coding analysis.
How does trypsin digestion affect peptide detection in mass spectrometry?
Trypsin cleaves proteins at lysine and arginine residues to generate peptide fragments for mass spectrometry identification. Very short peptides and microproteins produce fragments too small for reliable database matching, which means they are frequently missed in standard proteomics workflows without additional enrichment steps.
What purity standard should researchers require for synthetic peptides?
Research-grade synthetic peptides should be verified at greater than 99% purity through HPLC and confirmed by LC-MS for sequence identity. Certificate of Analysis documentation from third-party testing provides the traceability required for reproducible experimental results.